Recipe Web Scraper
Project Overview
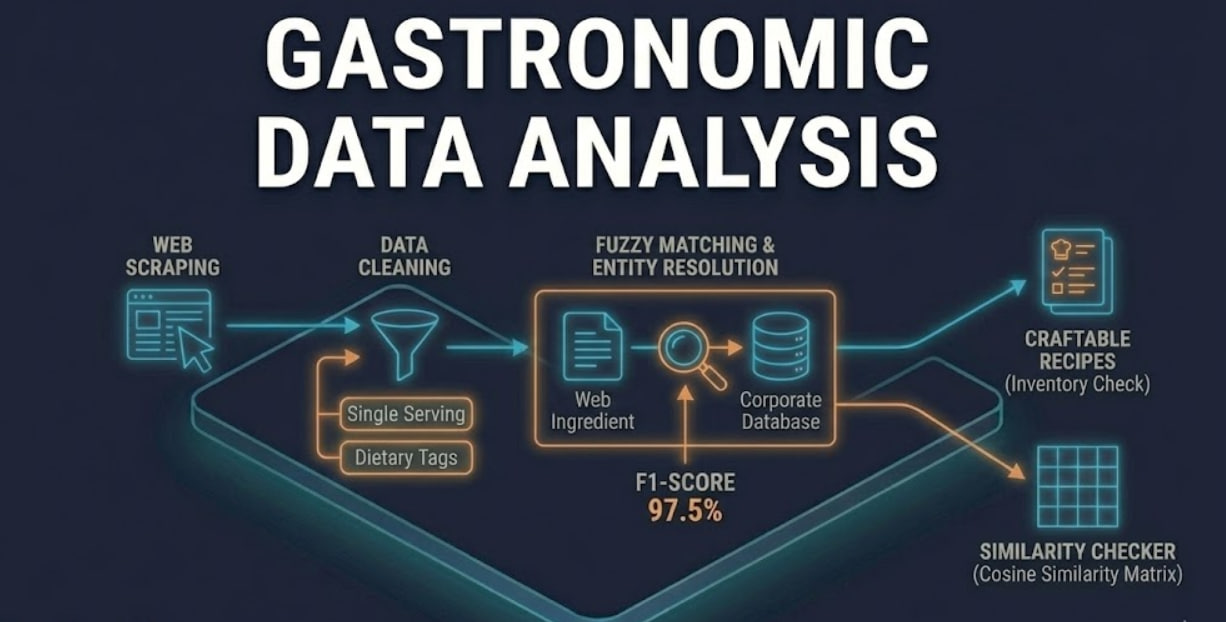
This project is a specialized Data Mining tool designed to build the datasets used in my Gastronomic Data Analysis research. It is a Python-based Web Scraper capable of navigating culinary websites to extract structured information about recipes, organizing them by “Courses” (Portate) like Appetizers, Main Courses, or Desserts.
Multi-Language Support 🇮🇹 🇬🇧
The repository includes documentation in both languages to assist developers:
- English: Detailed explanation of the JSON structure and CLI usage.
- Italian: “Note esplicative” and examples.
Technical Features
1. Structured Data Extraction
The scraper converts unstructured HTML web pages into a clean, machine-readable JSON format. Each recipe is parsed into specific fields:
- Metadata: Title, Description, Acquisition Timestamp, Source Link.
- Core Data: Instructions (Steps) and Ingredients (Name + Amount).
2. Politeness & Anti-Bot Mechanism 🤖
To avoid IP bans and respect the target server’s resources, the script implements a Dormancy Mechanism.
The user can specify a dormancy_time (in seconds) via CLI. The scraper sleeps between requests, simulating human-like browsing behavior.
3. Configurable Targets (portata.conf)
Instead of hardcoding URLs, the tool uses a configuration file (portata.conf) allowing non-programmers to easily update the list of target categories (courses) without touching the codebase.
Note
This tool was specifically built to populate the dataset for the Gastronomic Data Analysis research project.
Usage Example
The tool is executed via command line, specifying the target course and the delay:
# Syntax: python scrapingPortata.py [Course] [Delay_Seconds]
python scrapingPortata.py antipasti 1