Gastronomic Data Analysis
Project Overview
This project implements an automated pipeline to scrape, clean, and analyze culinary data from major Italian recipe websites (e.g., Dissapore). The goal was to build a structured dataset, perform statistical analysis on ingredient usage, and implement advanced matching algorithms to map ingredients against an external corporate database (Planeat).
The system allows for identifying craftable recipes based on available inventory and computing a Recipe Similarity Matrix to suggest related dishes.
Technical Workflow
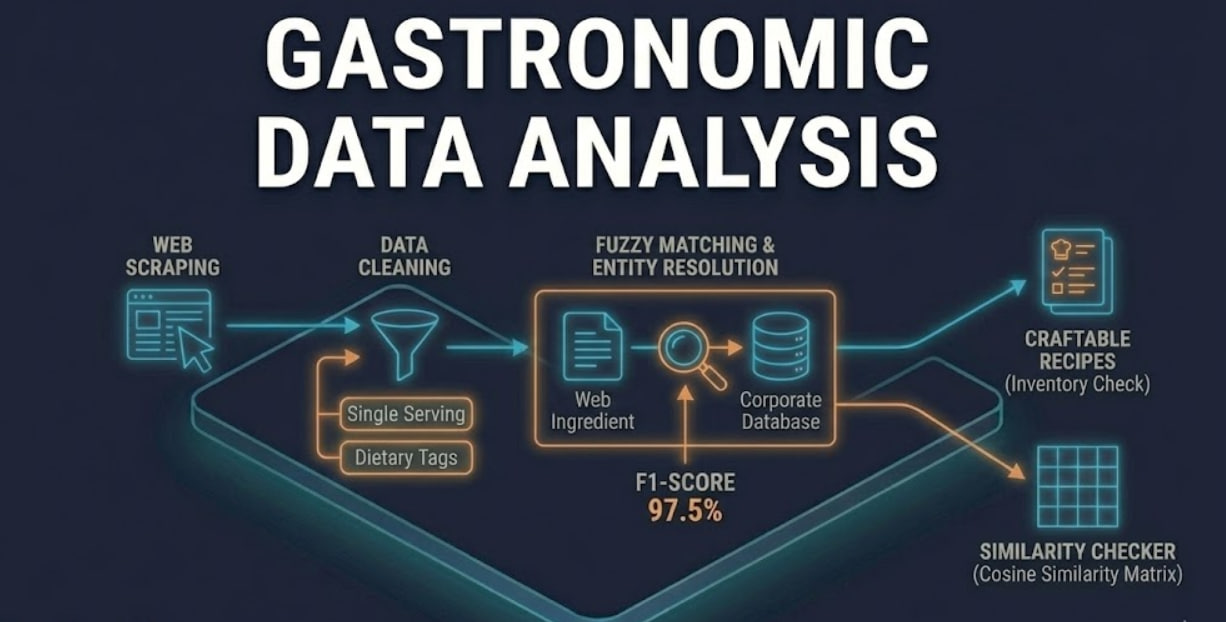
The project is structured in sequential modules:
1. Web Scraping & Data Collection
I developed custom scripts in Python to crawl recipe websites.
- Input: Category selection (e.g., Starters, Main Courses).
- Process: Automated extraction of titles, instructions, and ingredients with random dormancy intervals to avoid IP banning.
- Output: Structured JSON files containing recipe metadata.
2. Data Cleaning & Normalization
Raw data is processed to ensure consistency:
- Conversion of all quantities to single-serving portions.
- Extraction of nutritional values (Kcal) and dietary tags (Gluten-Free, Lactose-Free).
- Generation of a master
Cookbook_SingleServing.jsondataset.
3. Fuzzy Matching & Entity Resolution
One of the core challenges was mapping ingredients scraped from the web (unstructured) to a rigid corporate database (SQL). I implemented and tested 6 different Fuzzy Matching models using string similarity metrics.
- Validation: A validation set of 1000 pairs was manually annotated (Ground Truth).
- Results: Model #2 achieved the highest F1-Score, successfully mapping 975 ingredients with high precision.
4. Advanced Analytics
- Craftable Recipes: An algorithm that cross-references the mapped ingredients with the corporate inventory to determine which recipes can be cooked immediately.
- Similarity Checker: Computes a similarity score between recipes using Cosine Similarity on ingredient vectors. This generates a matrix useful for recommendation systems (e.g., “If you like Carbonara, you might like Gricia”).
Tools & Libraries
- Language: Python 3.x
- Data Processing: Pandas, NumPy
- Scraping: BeautifulSoup / Requests
- Math/Logic: FuzzyWuzzy, Scikit-learn (for similarity metrics)
Developed as part of the Master’s Thesis under the supervision of Prof. Tullio Facchinetti (University of Pavia).
